Stay Ahead of the Curve
Latest AI news, expert analysis, bold opinions, and key trends — delivered to your inbox.
Stax Is Google’s Quiet Revolution in AI Evaluation
3 min read Google just launched Stax — a toolkit that finally treats LLM testing like real engineering. Structured evals. Custom scoring. Prompt A/B tests. It’s a quiet release, but a loud signal: guesswork isn’t good enough anymore. September 03, 2025 16:19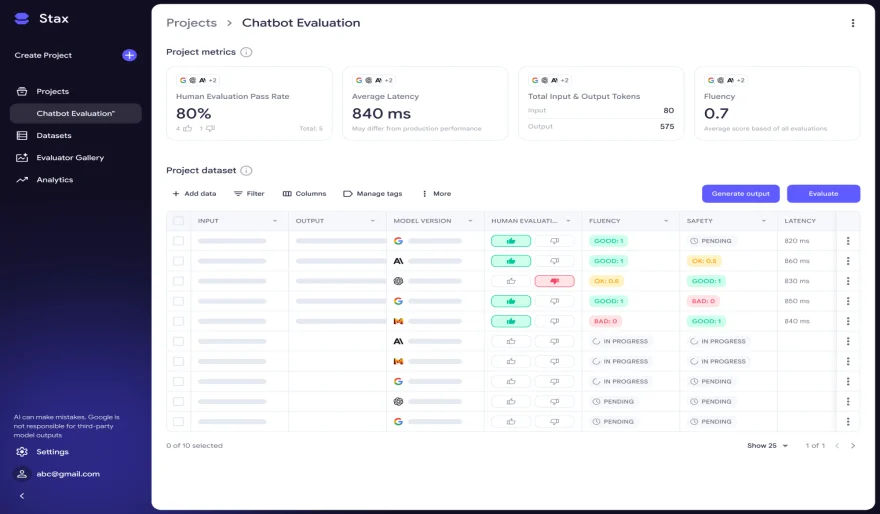
What it is:
Google recently introduced Stax, a developer-focused evaluation toolkit for large language models (LLMs). Aimed at replacing unreliable “vibe testing,” Stax enables teams to create structured, repeatable assessments that go beyond leaderboard scores. It’s backed by Google DeepMind and Google Labs for both experimental innovation and evaluation rigor.
Core Features:
-
Custom evaluation pipelines — Developers can upload their own test datasets (e.g., via CSV) or generate them within Stax.
-
Pre-built “autoraters” — These are LLMs that act as judges to score outputs on standard dimensions like coherence, factual accuracy, or brevity.
-
Custom “autoraters” — The standout feature: you define your own scoring logic—brand voice, compliance checks, safety, etc.
-
Quick Compare — Enables fast A/B tests of models or prompts, yielding rapid feedback for iteration.
-
Analytics dashboards — Provide visibility into performance, latency, token usage, and more—making evaluation data-driven and transparent.
Why it matters:
Stax addresses a crucial pain point in LLM development: non-deterministic outputs that make traditional unit testing ineffective. By codifying your real-world goals into concrete metrics—and tracking them over time—it turns evaluation from guesswork into engineering.



















 AI Agents
AI Agents